【Python】並行ハンバーガー、並列ハンバーガー
はじめに
非同期アプリケーションに興味があり、FastAPIの「並行処理とasync / await」のドキュメントを読んでいて「並行ハンバーガー」と「並列ハンバーガー」という話が面白いと感じたので、知見を深めるため実装してみた話になります。
リポジトリは以下になります。
使用技術
Python3.12
並行ハンバーガー
早速ですが、並行ハンバーガーを実装していきます。
詳しい詳細はドキュメントを参照ください。
https://fastapi.tiangolo.com/ja/async/#_5
ChatGPTに要約してもらいました↓
主人公は好きな人と一緒にファストフードのレストランに行き、豪華なハンバーガーを注文します。レジ係は他の注文を処理している間に、その準備が始まることをキッチンに伝えます。待ちながら、好きな人と楽しく過ごし、彼女に夢中になります。そして、待ちに待ったハンバーガーが出来上がり、一緒に楽しい食事の時間を過ごします。
ここで重要になってくるのが、何かを待っている間に別のことをするという点です。
具体的には、ハンバーガーを準備している間に好きな人と会話をするというところになります。
それでは実装したプログラムを見ていきます。
並行処理の実装には標準ライブラリのasyncioを使用しています。
ここでは大きく2つのタスクグループを作成しています。
- 注文をして支払い料金の準備中にキッチンに注文内容を伝えて、番号札を渡すタスクグループ
- ハンバーガーの準備中に好きな人と会話をするタスクグループ
各関数内のawait asyncio.sleep()の箇所は時間のかかる行動(処理)だと考えてください。
時間のかかる行動(処理)が始まった場合には、タスクグループに登録されている別の行動(処理)が実行されます。
このように各行動(処理)を切り替えながら行うことで、何かを待っている間に別のことをするということを実現しています。
プログラムの実行結果は以下のようになります。
同等の処理を逐次処理で行う場合、最低でも待ち時間の40秒はかかってしまいます。
並行処理を使用することで28秒で処理できていることがわかります。
並列ハンバーガー
続いて、並列ハンバーガーを実装していきます。
詳しい詳細はドキュメントを参照ください。
https://fastapi.tiangolo.com/ja/async/#_6
こちらも同じくChatGPTに要約してもらいます。
好きな人と一緒にファストフードを買いに行きます。レジ係が複数いて、一人が注文を受けると同時にハンバーガーを準備し始めるため、前の人がカウンターを離れずに待っています。あなたの番になり、豪華なハンバーガーを注文し、支払いをします。レジ係はキッチンに行き、あなたはハンバーガーができるのを待ちます。あなたと好きな人は他の人に取られないように注意しながら、ハンバーガーを待ちます。ハンバーガーができて渡されたら、テーブルに行って食べます。
こちらで重要になるのが複数人のレジ係がいる点です。
複数人でそれぞれの注文を受け、ハンバーガーの準備をしてハンバーガーを渡します。
並行ハンバーガーとは違い、注文を受けるところからハンバーガーの準備等の全てを行なっています。
それでは実装したプログラムを見ていきます。
並列処理の実装には、標準ライブラリのconcurrent.futuresのProcessPoolExecutorを使用しています。
こちらでは注文からハンバーガーの準備、ハンバーガーを食べるまでを一つの行動(処理)として、2人の注文を同時に処理しているプログラムになっています。
(10秒で完成するハンバーガーと15秒で完成するハンバーガーを同時に処理しています。)
プログラムの実行結果は以下のようになります。
ハンバーガーの準備等で待ち時間が発生しますが、待ち時間の間に別の処理をすることはできないので今回のパターンではあまり効率的でないことがわかります。
まとめ
ドキュメント内の「ハンバーガーのまとめ」にも記載されていますが、並行ハンバーガーと並列ハンバーガーの大きな違いは待ち時間がある場合に別のことができるかできないかになるかと思います。(並列の方が優れているという話ではない。)
Webアプリケーションに落とし込んで考えてみた時に、DBへの書き込みや読み取り、ファイルへの出力等のI/O(input / output)が発生する箇所に並行処理を使用してあげることでユーザー体験の向上が考えられるのではないかと感じています。
ただ、気になる点としてDBのトランザクション関係はどのように動くのか、どのように制御するべきなのかや実際パフォーマンスはどれくらい変わるのかは知見がないので、学習も兼ねて別途記事にまとめたいと考えています。
おまけ「並列家掃除」
https://fastapi.tiangolo.com/ja/async/#_8
上記で並列処理の使い所的なことで家掃除が例にあげられていたので、こちらも簡単にですが実装してみました。
実装したプログラムは以下になります。
こちらでは、リビングルームとキッチン、バスルーム、ベッドルームを同時に掃除する想定で実装しています。
掃除する人が複数人いるイメージです。
プログラムの実行結果は以下のようになります。
1人(逐次処理)で掃除をするより遥かに効率的に掃除をすることができるので満足できます。
Hagging Face Inference APIをFastAPIで使用してみた
はじめに
#97のみんなのPython勉強会のトーク1草薙 昭彦さんの
『Postmanで始めるAI・機械学習プラットフォームHugging Face』
の内容が興味深く、実際にAIを利用してみたいと思ったので実際にやってみましたという記事です。
トーク内で使用されていた資料も公開されていました!
Postmanで始めるAI・機械学習プラットフォームHugging Face - Speaker Deck
実装したもの
FastAPIを使用してSwaggerから簡単に利用できるようにしました。
API: https://inference-api-with-fastapi-2nc47pcv3a-an.a.run.app/docs
リポジトリ: GitHub - ryu-0729/inference_api_with_fastapi
使用技術
Python3.12
FastAPI
Docker/Dev Container
Cloud Run
Hagging Face Inference API
Hagging Face Inference APIの利用方法
トーク内の資料でも紹介されてはいますが、一通りの流れを記載いたします。
Step1 Hugging Faceにユーザー登録
メールアドレスとパスワードを入力してユーザー登録をします。
登録したメールアドレスに認証メールが届くので認証を完了します。

Step2 アクセストークンの取得
ユーザーの設定画面から左側の「Access Tokens」を選択します。

「New Token」のボタンからアクセストークンを生成します。
Roleはreadで問題ないです。

Step3 Hagging Face Inference APIの利用
PostmanからのAPIの利用方法は、資料に記載がされているのでここでは省略いたします。
15 ~ 21ページに記載されています。
https://speakerdeck.com/nagix/postmandeshi-meruaiji-jie-xue-xi-puratutohuomuhugging-face?slide=15
Python(FastAPI)からの利用方法
今回はrequestsパッケージを使用してAPIを利用します。
エンドポイントさえ設定できれば簡単にAPIを利用することができます。
上記のリンクに記載されていますが、エンドポイントの形式は、「共通URL + モデルID」になります。
ENDPOINT = https://api-inference.huggingface.co/models/<MODEL_ID>
利用するモデルは下記リンクを見てみて設定するか、ご自身で調べて設定する形になります。
https://huggingface.co/docs/api-inference/detailed_parameters#detailed-parameters
また、Step2で生成したアクセストークンをAuthorizationヘッダーに渡すことも必要になります。
形式は「Bearer + アクセストークン」になります。
"Authorization": f"Bearer {access_token}"
参考ソース(Postmanのコード生成を利用)
import requests import json url = "https://api-inference.huggingface.co/models/SamLowe/roberta-base-go_emotions" payload = json.dumps({ "text": "I am not having a great day." }) headers = { 'Content-Type': 'application/json', 'Authorization': 'Bearer xxxxxxxxxxxxxxx' } response = requests.request("POST", url, headers=headers, data=payload) print(response.text)
今回実装したソースコードについては下記を参照していただければと思います。
https://github.com/ryu-0729/inference_api_with_fastapi/blob/master/app/core/requestapi.py
https://github.com/ryu-0729/inference_api_with_fastapi/blob/master/app/apis/text.py
※ 注意事項
初回アクセスの際に、モデルの読み込みによってAPIエラーになる場合がありました。
しばらく時間を置いて実行することで正常に動作することが確認できました。
実行例

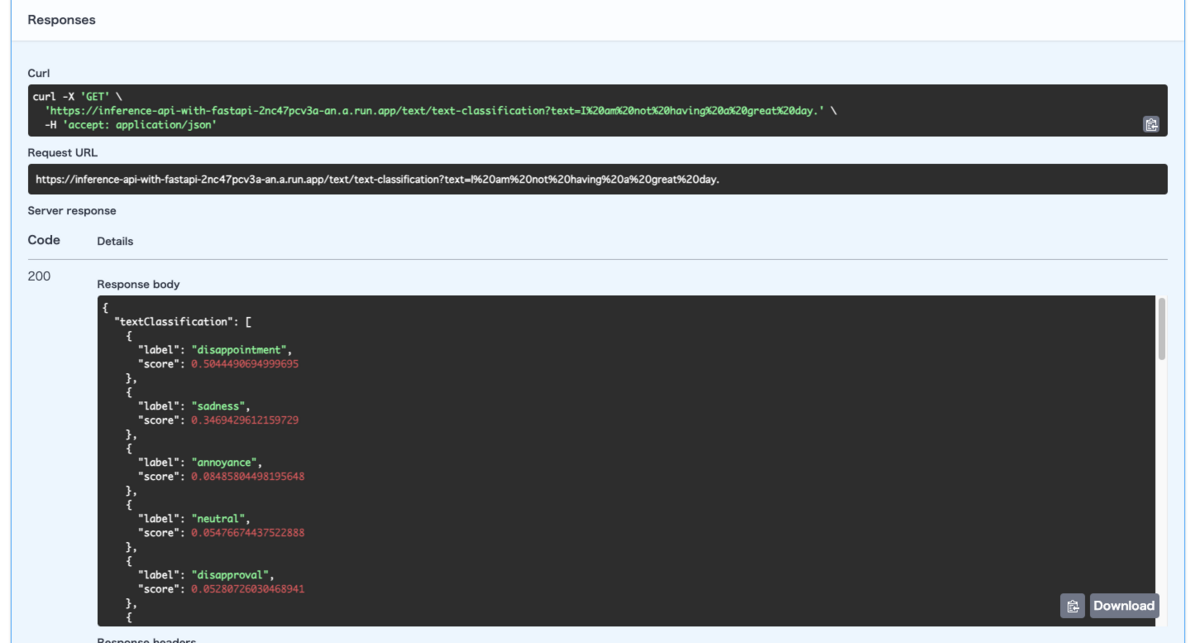
使用したInference APIについて
今回使用したInference APIについて紹介したいと思います。
テキストから感情分析 Text Classification
https://huggingface.co/docs/api-inference/detailed_parameters#text-classification-task
テキストから感情を分析するAPIです。
分析したいテキストをパラメータとして渡すと感情ごとに一致度を数値としてレスポンスが返ってきます。
テキストの問題に答える Question Answering
https://huggingface.co/docs/api-inference/detailed_parameters#question-answering-task
テキストの問題に答えるAPIです。
問題文とテキストをパラメータとして渡すと問題に答えるレスポンスが返ってきます。
画像からテキストを生成 Blip Image Captioning Large
https://huggingface.co/Salesforce/blip-image-captioning-large
画像URLからテキストを生成するAPIです。
画像URLをパラメータとして渡すとどのような画像であるかをテキストにしてレスポンスが返ってきます。
まとめ
Hagging Face Inference APIをPython(FastAPI)から使用してみたわけですが、想像以上に簡単に利用することができました。
今回使用したAPI以外にも画像生成や画像の感情分析とかも利用できるので、興味がある方は実際に触ってみると面白いと思います。
「みんなのPython勉強会」には毎月のように参加しているわけですが、毎月興味深い内容やPythonの技術について新しいことを知れる貴重な勉強会だと感じています。
感謝です!!
以上になります、ありがとうございました!
Pythonエンジニア認定実践試験合格備忘録
はじめに
はじめにですが、Pythonエンジニア認定実践試験という資格に合格できたのでなぜ受験したのかや勉強方法等をまとめていきます。
これから受験を考えている人の参考に少しでもなれればと思います。
お前誰よ
簡単に自己紹介をしていきたいと思います。
普段は宮城県の仙台市でプログラマーをしています。
↑歴としては3年目の年になります。(2023/10時点)
Python推しです!
勉強会にも参加したりしています。
業務で使用している技術(言語的なところ)
直近で使用しているのはPHPとGoが多いです。(Pythonではない。。。)
Pythonに関しては、競プロで使用するために学習し始めてニンテンドーSwitchの自動化に使用したり、画像処理をしたり、機械学習してみたり、個人開発(FastAPI)に使用したりしています。
業務ではDjangoのプロジェクトに少しヘルプで入ったことがある程度です。
受験理由
Python推しということもありますが、社内で少しずつPythonを使用していく風が吹き始めたので「こいつPythonできるぞ」というのを示したかったのが1番の理由です。(資格があるからできるとは一概に言えませんが)
また、業務ではPythonを触ることは無いに等しいので知識や技術を学ぶにも良い機会になると感じたのも理由になります。
勉強方法
勉強方法は主教材として紹介されているPython実践レシピを使いました。(試験の問題もここから出題されるので)
その他には下記の2つのサイトも使用しました。
それぞれどんな感じで勉強したかを簡単にまとめます。
1 Python実践レシピ
2~3周読み込みました。
1周目は試験範囲以外も読んでいます。
2周目以降はメソッドの使用用途や戻り値などを重点的に理解できるようにしました。
また実際にメモ程度にですが、ソースを書いてアウトプットするようにしました。
↓参考リポジトリ
2 ExamApp
実践問題の初級~上級までを100%解けるようにしました。
それぞれ3回程度やりました。
回答を間違った箇所は書籍を読んだりやソースを書いたりして理解できるようにしています。
3 ディープロ
これはExamApp以外の問題もやりたいなーと感じたのと公式サイトに記載されていたので挑戦してみました。(ExamAppのみで過学習しない的な感じです。)
↑無料プランです!
大体3回くらい実施しています。
まとめ
Pythonエンジニア認定実践試験を受験してみての感想は良かったと感じています。
Pythonの基本的なところも含めて、標準ライブラリの深掘りが出来たと個人的に思っています。
ただ、OS周りやファイルとディレクトリの扱い、インターネット上のデータを扱うらへんは理解するまでが大変でした。。。
試験は満点合格(1000点)を目指していたのですが、850点ということで若干悔しかったです😇
合格できたので良しとします!
【Switch自動化】ポケモンSVの学校最強大会を無限に周回した話
はじめに
前回、ニンテンドーSwitchを自動操作してポケモンSVの学校最強大会を周回するプログラムを作成しました。
その中で課題点/改善点に下記をあげていました。
ここでお気付きの方もいるかと思いますが、現状のプログラムだとニンフィアが途中でリタイアする可能性があるのです。。。
リタイアすると残り時間ポケモンセンターで回復し続けます。
また、時間による設定を行なっているので学校最強大会中に処理が終わることがほとんどになっています。。
よって今後の追加機能としては下記を考えています。
今回はこれら課題点/改善点を解決するべく機能追加を行なって学校最強大会を無限に周回できるようにしました。
実装したソースコードは下記にあります。
インストールや実行方法はREADMEに記載してあります。
追加機能
大きく追加した機能はこちらです!
- レポート判定機能
- リエントリー機能
それではそれぞれの機能についてどのような機能でどのように実装したか解説したいと思います。
レポート機能
機能としては学校最強大会をエントリーする場所でレポートを書く機能になっています。

実装方法ですが、レポートを書くかどうかを判定する必要があります。
レポートを書くかどうかの判定には画像処理(OpenCV)を使用しています。
具体的には画像処理を使用して画面上に、「学校最強大会」が表示されているかどうかを判定している感じになります。
主な処理の流れとしては下記になります。
- 画面上の画像取得
- 取得画像をトリミング
- 2でトリミングした画像と比較元画像を2値化*1
- 3の2つの画像(正確にはNumPy配列)を比較し一致している要素を取得
- 4で取得した一致している要素数が閾値を超えているか判定
- 閾値を超えている場合はレポートコマンドを実行
3の比較元画像↓

2値化した比較画像↓

このレポート機能を実装することで、課題点/改善点であった下記を達成することができます。
- 学校最強大会が終了した時点で処理が終わるようにする。
- レポート機能
この自動化プログラムは終了したい時間を設定するようになっているので、終了時間を過ぎているかつレポートを書いたタイミングで処理を終了させることで学校最強大会が終了した時点で処理を止めることができるようにもなっています。
リエントリー機能
機能としては、学校最強大会でリタイアしてポケモンセンター送りになった際に学校最強大会にリエントリーする機能になっています。
この機能を実現できたのは1番の要因は先程紹介したレポート機能にあります。
レポート機能がなかったら実現できなかったと言っても過言ではありません。
なぜレポート機能が必要だったのかについて説明していきたいと思いますが、まずは処理の流れを紹介していきます。
- 画面上の画像取得
- 取得画像をトリミング
- 2でトリミングした画像と比較元画像を2値化
- 3の2つの画像(正確にはNumPy配列)を比較し一致している要素を取得
- 4で取得した一致している要素数が閾値を超えているか判定
- 閾値を超えている場合はゲーム終了、再起動コマンド実行
リタイアしたかどうかの判定処理はレポート機能と同じ方法になります。
なぜレポート機能が必要だったのか気付いた方もいるかもしれませんが、このリエントリー機能はリタイアしたかどうかを判定して、リタイアしていればゲームを終了して再度ゲームを開始する流れになっているため、学校最強大会終了後にレポートを書く機能が必要になっていました。(レポートを書いていないとこれまでの周回が無駄になる。。)
ただしリエントリー機能では比較画像を工夫する必要がありました。
当初、判定用の画像は「目の前が真っ暗になった」やポケモンセンターで回復をしてもらう際の文言で比較しようと思ったのですが、画像の取得が不安定であったり同じような要素が他の箇所にも存在するため、判定がうまくできていませんでした。
なので少し強引ではありますが、ポケモンセンターのわざマシンの場所を使って判定するようにしています。
ポケモンセンターにいる時に取得できる画像↓

比較元画像↓

そしてこのリエントリー機能を実現することによって下記の課題点/改善点は達成することができました。
- ポケモンセンターに戻った際は学校最強大会にリエントリーできるようにする。
比較元画像についてゲーム内の時間帯それぞれで正しく判定できるの?という疑問を持つ方もいるかもしれませんが、問題なく判定できることは検証済みなのでご安心を!
補足:下記の機能も課題点/改善点で挙げていましたが、リエントリー機能があるのでいらないかなということで実装はしていません。
ソースコード
学校最強大会無限周回プログラム↓
カスタムクラス↓
最後に
個人的にですが、学校最強大会周回のプログラムは満足のいくものが出来上がったと感じています。
ガンガン稼いでポケモン育成頑張ります!
テラピース難民を救うため自動レイドにも挑戦したいですね。。。
ここまで読んでいただきありがとうございました!
【ポケモンSV】switchを自動操作して学校最強大会を周回してみた話
はじめに
とある勉強会にてswitchを自動操作するという話を聞き、やってみたい気持ちが強すぎたのでやってみました。
作成したものはこちらになります。
プログラムの簡単な説明ですが、ポケモンSVの学校最強大会でニンフィアを重労働させるプログラムになっています。
毎度のことながらポケモンを育成していくにあたってお金は大切ですので、仕事に行っている間や寝ている間にニンフィアに休まず働いてもらいましょう。
※ 重労働させるポケモンは自由です。
2023/04/03追記
本記事の強化版、学校最強大会を無限に周回するプログラムを作成したのでそちらも是非見てください!
使用技術とシステム構成
GitHubのREADMEにも記載していますが下記になります。
- Raspberry Pi 3 Model B
- Raspberry Pi OS
- nxbt
- Python3.9
- Bluetoothアダプタ
自動化にあたってswitchをBluetooth接続する際に、joycontrolの使用を考えていたのですが、最新のswitchのバージョンでは動作が不安定らしいので下記のnxbtを使用することにしました。
インストールから使用するまでが簡単だったので感謝してます。
なんといってもデモで動作を見ることができたので実装イメージが持ちやすかったです。
環境構築
環境構築はREADMEに記載してあるので簡単に流れを説明していきます。
Step1
まずはラズパイのセットアップを行なっていきます。
やることとしては下記の2つの記事が参考になります。
Step2
依存関係のアップデート
$ sudo apt update $ sudo apt upgrade
Step3
重労働プログラムのcloneとnxbtのインストール
$ git clone -b old_making_money https://github.com/ryu-0729/switch-pokemonsv-auto-project.git $ cd switch-pokemonsv-auto-project $ sudo pip3 install nxbt
Step4
内部Bluetoothの無効化と外部Bluetoothの接続
ここは地味にハマった箇所になるので意外と重要だと思っています。
こちらの記事の方法で実現しました。
ハマった理由としては、デモの実行の際には特に外部Bluetoothを接続する必要はなく動作することが確認できていたので、原因の特定まで時間がかかってしまいました。(恥ずかしい。。)
Step5
重労働させるポケモンの準備
こちらはポケモンSV側での準備になります。
重労働させたいかつ学校最強大会を1ウェポンで勝ち抜けるポケモンを準備してください。
ここまで準備が終わればあとはプログラムを実行するのみです!
プログラムの解説
では簡単に重労働プログラムの解説をしていきたいと思います。
下記ソースになります。
nxbtのリポジトリに用意してくれているdemo.pyファイルをカスタマイズした形になります。
やっていることはシンプルで、59行目のstart_game(controller_index)でコントローラーの接続画面からゲームを起動までを行なっています。
64行目のafter_hour = datetime.timedelta(hours=0, minutes=30)の引数で労働時間を決めます。(デフォルトでは30分)
あとは70行目以降で指定した時間までひたすらRボタンとAボタンを連打するようになっています。
Rボタンを押している理由は、ニンフィアの育成が中途半端なためテラスタルをして火力を底上げしています。。。。
それでは始業時間です。
$ sudo python makingMoney.py
実際の動作
簡単にではありますが、重労働させている様子を撮影しました。
課題点/改善点
ここでお気付きの方もいるかと思いますが、現状のプログラムだとニンフィアが途中でリタイアする可能性があるのです。。。
リタイアすると残り時間ポケモンセンターで回復し続けます。
また、時間による設定を行なっているので学校最強大会中に処理が終わることがほとんどになっています。。
よって今後の追加機能としては下記を考えています。
- 条件判定を行い回復アイテムを使用する。(社内でフィードバックがありニンフィアの努力値のH180をSに振ったらあまりリタイアすることはなくなったので要検討)
- ポケモンセンターに戻った際は学校最強大会にリエントリーできるようにする。
- 学校最強大会が終了した時点で処理が終わるようにする。
- レポート機能
上記の機能は主に下記の記事を参考にOpenCVやOCRを使用して実現したいと考えています。
また、将来的には物体検出の技術を使用してなんやかんやできたら面白いかなと密かに思っています。
最後に
ここまで読んでいただきありがとうございます!
初の自動化に挑戦してみたわけですが、nxbtがとても使いやすく比較的簡単に自動化することができました。
また、外部の勉強会にはなりますが自動化に興味を持つきっかけをいただきとても感謝しています。
ありがとうございました。
【Python】bit演算 `&`(論理積, AND)演算子の豆知識
今回はbit演算で使用できる&演算子についての豆知識的なのをまとめていきたいと思います。
&演算子とは
簡単にまとめると比較対象を2進数で表した時に同じ桁数が1であれば1を返し、そうでない場合(0の時)は0を返すといった感じになります。
3 & 2の場合 3 = 011 2 = 001 --------- 1 = 001 6 & 4の場合 6 = 110 4 = 100 --------- 4 = 100
偶奇判定
偶奇を判定するプログラムで&演算子を使用してみると、こいつ知ってるな感が出ます。
ただし、言語によってはand(かつ)を表す&&があり読み手が勘違いする場合もあるので、使用する場合には自己責任でお願いいたしますー
if x & 1: # 奇数処理 else: # 偶数処理
シフト演算子との利用
これは主にbit全探索の実装の際に使用する書き方ですが、簡単にまとめると1と0のフラグ判定処理みたいなイメージになります。
下記bit全探索の実装から抜き出したものになります。
if (i >> j) & 1: # フラグが立っている場合の処理
具体的な数値で見てみましょう。
・i = 5, j = 1の場合 5(101)を右に1シフトしてANDを取ります。 -> 010になります。 よって010 & 001(1)をすると000になります つまりフラグが立っていないことがわかります。 ・i = 5, j = 2の場合 5(101)を右に2シフトしてANDを取ります。 よって001 & 001をすると001になります。 つまりフラグが立っていることがわかります。
最後に
実際、Web開発現場でbit演算や2進数を意識して実装をしなければならない状況にはなったことがないので、使用することは少ないかと思われますが「へー」くらいで流していただければと思いますー
【Python】期待値の計算
期待値の計算のアルゴリズムを簡単にまとめていきたいと思います。
期待値とは
確率論において、確率変数の期待値(きたいち、英: expected value)とは、確率変数のすべての値に確率の重みをつけた加重平均である。確率分布に対して定義する場合は「平均」と呼ばれることが多い
出典: フリー百科事典『ウィキペディア(Wikipedia)』
ウィキペディアには上記のように記載されていますが、簡単にまとめると「1回の試行で得られる平均的な値」のことを期待値と言います。
大まかな例を挙げるとすると、ある賭け事があるとします。
その賭け事では、0.1%の確率で10000円、0.3%の確率で5000円、0.6%の確率で0円のリターンがあります。
この場合の期待値の計算方法は、
(10000 * 0.1) + (5000 * 0.3) + (0 * 0.6) = 2500(円)
になります。
よって、この賭け事の期待値は「2500円」という結果になります。
つまり、2500円以上を賭けてしまうと損であるということになります。
また、期待値の計算については「期待値の線形性」という性質があるので下記にまとめたいと思います。
期待値の線形性とは
期待値の線形性というのは、複数の期待値の和を求めたい場合に期待値は複数の期待値の和になる性質のことを言います。
例としては、1回目の施行の期待値をX1とし、2回目の施行の期待値をX2とします。
この場合に1回目と2回目の合計の期待値は「X1 + X2」になります。
1回目と2回目の期待値の合計 = 1回目の期待値(X1) + 2回目の期待値(X2)
これはN回の期待値の合計を求める際にも使用することができます。
1回目、2回目...N回目の期待値の合計 = 1回目の期待値 + 2回目の期待値... + N回目の期待値
では実際に、期待値を求めるプログラムを書いていきます。
2つのサイコロの期待値を求める
問題は上記になります。
こちらの問題で考えることとしては、先ほどの「期待値の線形性」を利用して「出目の合計の期待値」を求めることになります。
(出目の合計の期待値) = (青の出目の期待値) + (赤の出目の期待値)
出目の合計の期待値は上記の式のように表せるため、これを求めることで答えを導き出すことができます。
n = int(input()) b = list(map(int, input().split())) r = list(map(int, input().split())) blue, red = 0.0, 0.0 for i in range(n): blue += b[i] / n red += r[i] / n print(blue + red)
ランダムに選択する場合の期待値
問題は上記になります。
こちらの問題でも「期待値の線形性」を利用して「合計点数の期待値」を求めることを考えましょう。
(合計点数の期待値) = (1問目の点数の期待値) + (2問目の点数の期待値) + ... + (N問目の点数の期待値)
合計点数の期待値は上記の式のように表せるため、これを求めます。
n = int(input()) answer = 0.0 for i in range(n): p, q = map(int, input().split()) answer += q / p print(answer)
最後に
今回は期待値の求め方と考え方について簡単にまとめてみました。
期待値を求めるテクニックとして足された回数を考えるというのもあるみたいなので、別の記事としてまとめたいと思います。